Home
The Baum-Welch algorithm for the weather-system HMM
Given a hidden Markov-chain (HMM), consisting of a set of states (which are hidden) and observations, the goal is to estimate the parameters of the system. Here, the parameter set consists of the transition matrix \(A\), the emission matrix \(B\) and the initial starting probabilities \(\pi\). If \(N\) is the amount of states, \(M\) the amount of possible observations in each timestamp and \(T\) the amount of timestamps of the system (discrete integers), then \(A\) is a \(N\times N\) matrix where \(a_{i,j}=\mathbb{P}(S_{t+1}=j\ |\ S_t=i\text{ for all }t)\) (being the probability that the next state \(S_{t+1}\) will be \(j\) given the current state \(i\)), \(B\) is a \(N\times M\) matrix where \(b_{i,k}=b_i(O_t)=\mathbb{P}(O_t=k\ |\ S_t=i\text{ for all }t)\) (being the probability that we observe \(O_t\) to be k given that we are in state \(i\)) and \(\pi\) is a vector of length \(N\) where \(\pi_i=\mathbb{P}(S_1=i)\) (being the probability that the HMM started in state \(i\)).
The first step in the algorithm is making a guess for the values of \(A\), \(B\) and \(\pi\) to initialize them.
Expectation Step
The second step is called the expectation-step, where we estimate the probability that the observations that we saw came from the parameters \(\theta=(A,B,\pi)\) that we currently have.
This step consists of the so-called forward and backward algorithm.
Forward algorithm
In the forward algorithm, we estimate the probability that the observed sequence of the HMM from \(t=1\) to \(t=t\), ended in state \(i\), we denote this by \(\alpha_t(i)=\mathbb{P}(O_1,...,O_t,S_t=i)\). For this, we first initialize \(\alpha_1(i)=\pi_i b_i(O_1)\), (the probability that we were in state \(i\) at the beginning times the probability that the first observation (\(O_1\)) occured during state \(i\)). Then, we compute
\(\alpha_t(j)=b_j(O_t)\sum_i\alpha_{t-1}(i)a_{i,j}\)
recursively. So we consider all ways to reach state \(j\) from previous states \(\alpha_{t-1}(i)a_{i,j}\) multiplied by the probability of seeing observation \(O_t\) in state \(j\).
Backward algorithm
In the backward algorithm, we do the opposite: we estimate the probability of observing the future from \(t=t+1\) onward, given state \(i\) at time \(t\). We denote this by \(\beta_t(i)=\mathbb{P}(O_{t+1},...,O_T\ |\ S_t=i)\). We initialize \(\beta_T(i)=1\) (since there is no future at \(t=T\)), and then we compute recursively again:
\(\beta_t(i)=\sum_j a_{i,j}b_j(O_{t+1})\beta_{t+1}(j)\)
So here we are considering the sum over all possible future states \(j\) (the sum of the product of the probability of moving from state \(i\) to \(j\) times the probability of observing \(O_{t+1}\) during state \(j\) times the probability of having gotten to the next state \(S_{t+1}\)).
Next, we compute \(\gamma\in\mathbb{R}^{T\times N}\) where \(\gamma_t(i)=\mathbb{P}(S_t=i\ |\ O_1,...,O_T)\) (the probability that we were in state \(i\) at time \(t\) given the observations), by
\(\gamma_t(i)=\frac{\alpha_t(i)\beta_t(i)}{\sum_j\alpha_t(j)\beta_t(j)}\)
The way we get this formula, is by transforming the formula for gamma: \(\gamma_t(i)=\mathbb{P}(S_t=i\ |\ O_1,...,O_T)=\mathbb{P}(S_t=i,O_1,...,O_T)/\mathbb{P}(O_1,...,O_T)\) and splitting \(O_1,...,O_T\) into \(O_1,...,O_t\) and \(O_{t+1},...,O_T\) for each \(t\), and because \(\mathbb{P}(S_t=i,O_1,...,O_t)=\alpha_t(i)\) and \(\mathbb{P}(S_t=i,O_{t+1},...,O_T)=\beta_t(i)\) we get the formula for the numerator. The formula for the denominator follows from the fact that \(\mathbb{P}(O_1,...,O_T)\) is just the sum over all states \(j\) of \(\alpha_t(j)\beta_t(j)\) (we are considering the probability of having seen the given observations, no matter the end state).
Then we compute \(\xi\in\mathbb{R}^{T\times N\times N}\) where \(\xi_t(i,j)=\mathbb{P}(S_t=i,S_{t+1}=j\ |\ O_1,...,O_T)\) (the probability that we were in state \(i\) at time \(t\) and that the next state \(S_{t+1}\) will be \(j\), given the observations), by
\(\xi_t(i,j)=\frac{\alpha_t(i)a_{i,j}b_j(O_{t+1})\beta_{t+1}(j)}{\sum_{k,l}\alpha_t(k)a_{k,l}b_l(O_{t+1})\beta_{t+1}(l)}\)
We obtain this equation by further developing the formula for xi: \(\xi_t(i,j)=\mathbb{P}(S_t=i,S_{t+1}=j\ |\ O_1,...,O_T)=\mathbb{P}(S_t=i,S_{t+1}=j,O_1,...,O_T)/\mathbb{P}(O_1,...,O_T)\)
In the numerator, \(\mathbb{P}(S_t=i,S_{t+1}=j,O_1,...,O_T)=\alpha_t(i)a_{i,j}b_j(O_{t+1})\beta_{t+1}(j)\), we count the probability of having gotten to state \(i\) at time \(t\) whilst having transitioned into the next state \(j\), whilst also having observed state \(j\) at time \(t+1\), multiplied by the probability of observing \(O_{t+1},...,O_T\) in the future (being \(\beta_{t+1}(j)\)). In the denominator, we simply compute the same but summing over all possible states \(k,l\), accounting for the probability of having seen the observations no matter the (next) state of time \(t\).
Maximization Step
In the third step, the maximization step, we update the parameters \(\theta=(A,B,\pi)\) using the estimated probabilities from the previous step.
We compute the values for \(A\) by:
\(a_{i,j}=\frac{\sum_{t}^{T-1}\xi_t(i,j)}{\sum_{t}^{T-1}\gamma_t(i)}\)
So this is the ratio between every time we were in state \(i\) AND when the next state was \(j\), to every time we were in state \(i\).
We then compute the values for \(B\) by:
\(b_{i,k}=\frac{\sum_{t}^T\gamma_t(i)(1\text{ if }O_t=k\text{ else }0)}{\sum_{t}^T\gamma_t(i)}\)
So this is the ratio between every time we were in state \(i\) AND when we observed observation \(k\) at time \(t\), to every time we were in state \(i\).
We then repeat this procedure by going back to step 2. The algorithm will converge to a local extremum, but not necessarily the global optimum.
We can also compute the log-likelyhood of the system: \(\text{log}\sum_i\alpha_T(i)\). This will give a measure of certainty of the estimation of the parameters. This represents the log of the fraction of observation data that gets explained by the estimated parameters. The algorithm will converge to a certain value of this log-likelyhood and we detect how much this changes during every iteration step.
My implementation for the weather HMM will run the algorithm multiple times and then store every log-likelyhood and parameter instance estimated, and then compare.
Evaluating the model
After every time we run the training, meaning we exit if the desired error tolerance is reached or if too many attempts have been used, we first have to "align" the predicted parameters \(A\), \(B\) and \(\pi\) in the right direction.
The reason we have to do this is because when the model constructs the parameters, it predicts the values for \(A\), \(B\) and \(\pi\) up to a permutation only. Applying a different permutation to \(A\), \(B\) and \(\pi\) gives the same likelyhood of the data.
We therefor use the Hungarian method to find a best-fit assignment between the real values of the parameters and the estimated parameters, which corresponds to finding a correct permutation for the parameters.
https://en.wikipedia.org/wiki/Hungarian_algorithm
After having done this, I test the model on "future" data (not really future, since it's all synthetic), in two different ways.
Viterbi algorithm
I first assume the model has access to the future observation sequence, and I will test the model on its ability to generalize on estimating the underlying state sequence.
https://en.wikipedia.org/wiki/Viterbi_algorithm
For this, I store two structures \(\delta,\psi\in\mathbb{R}^{T\times N}\), where \(\delta_t(i)\) represents the maximum probability, over all possible state sequences, of seeing these states under the respective observation states, where the state at time \(t-1\) ends in \(i\), given the estimated parameters. So
\(\delta_t(i)=\underset{S_0,...,S_{t-1}}\max\mathbb{P}(S_0,S_1,...,S_{t-1}=i,O_1,...,O_T\ |\ \theta)\)
I initialize \(\delta_1(i)=\pi_ib_i(O_1)\) and then run over all future timestamps \(t=T+1\) until \(t=T_{\text{tend}}\), where I calculate dynamically:
\(\delta_t(i)=\underset{j}\max(\delta_{t-1}(j)a_{i,j})b_i(O_t)\)
So we compute the maximum probability of the previous timestamp multiplied by the transition probability, multiplied by the probability that we observed \(O_t\).
We also store
\(\psi_t(i) = \underset{j}{\mathrm{argmax}}\ \delta_{t-1}(j)a_{i,j}\)
which is the state \(j\), which given that the maximum probability path ended in state \(i\), is the most likely to have preceded state \(i\) at time \(t-1\).
Next, we initialize the predicted state sequence by setting
\(S_{T_{\text{end}}}=\underset{j}{\mathrm{argmax}}\ \delta_{T_{\text{end}}}(j)\)
and then iterate backwards:
\(S_t=\psi_{t+1}(S_{t+1})\)
Predictions when future observations are unknown
We also wish to evaluate the model on future data, assuming the current timestamp is \(t=T\) and we don't have knowledge of the future observations, like we did with the Viterbi algorithm.
For evaluating this, we will compute two arrays, namely the predicted state- and observation sequence.
We will iterate over all future timestamps, from \(t=T\) to \(t=T_{\text{end}}\), and compute the predicted states and observations from the previous values (dynamic programming). We denote \(\bar{S}_{t}\) for the predicted state at time \(t\) and \(\bar{O}_{t}\) for the predicted observation at time \(t\).
We initialize:
\(\bar{S}_{T+1}=\underset{j}{\mathrm{argmax}}\ \gamma_T(j)\)
so we take the most probable state \(j\) occuring at time \(T\). We also initialize the observation sequence as:
\(\bar{O}_T=\underset{j}{\mathrm{argmax}}\ b_T(j)\).
Here we take the most probable observation occuring under the current estimation of \(b\), given the predicted state of time \(T+1\). For the next timesteps, we can update the estimated distribution of states by doing \(p_{t+1}=p_tA\), and then computing
\(\bar{S}_{t}=\underset{j}{\mathrm{argmax}}\ (p_t)_j\)
\(\bar{O}_{t}=\underset{j}{\mathrm{argmax}}\ B_{\bar{S}_{t},j}\)
We can then simply count the fraction of correctly predicted states and observations by comparing the predictions to the actual "true" values.
Results
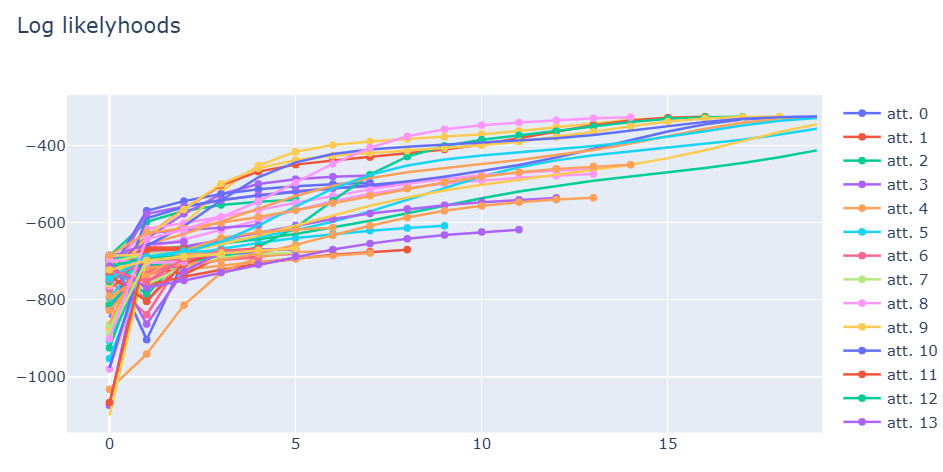
The log-likelyhoods evolve as expected: it shows non-decreasing behaviour and ends when the change gets small enough.
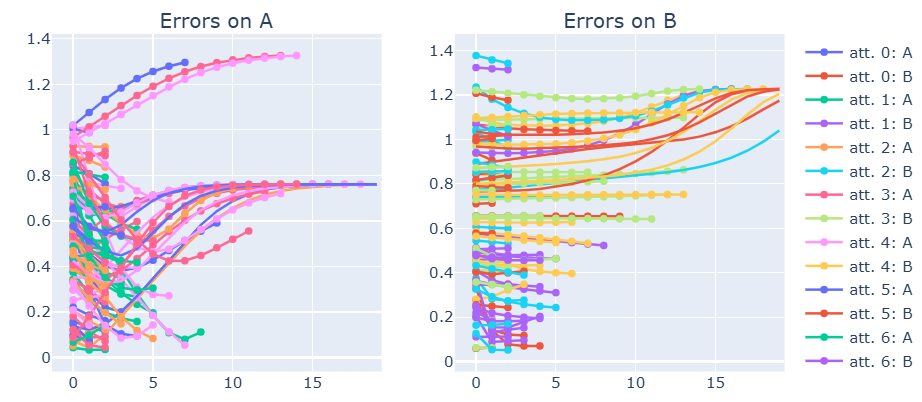
The errors in the estimation of the parameters \(A\) and \(B\) differ greatly between attempts: this is expected because the algorithm only finds local maxima, thus many initializations make the system evolve into a non-desirable estimation of the parameters.
Below are the prediction accuracies of the states that come after the ones from the training period.
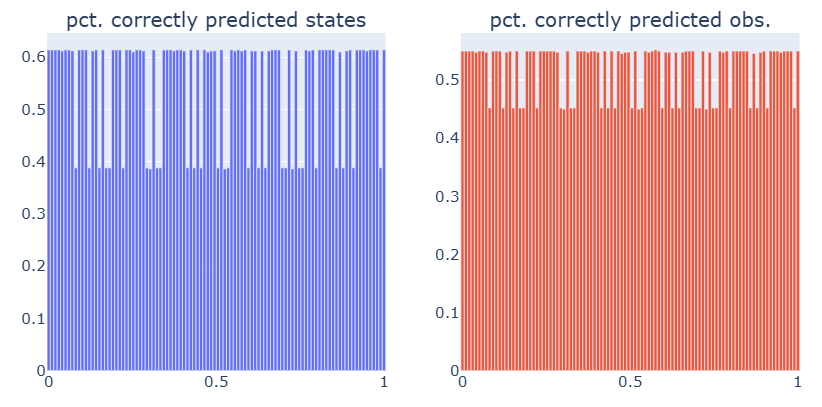
Below also shows the prediction accuraries of the guesses as well, but using the Viterbi-algorithm instead. Predictions are clearly more accurate using this method.